前段时间,谷歌报告了其在神经机器翻译上所取得的重大研究进展,并也实现了 Google Translate应用上汉语-英语翻译的商品化(参阅《谷歌翻译整合神经网络:机器翻译实现颠覆性突破》和《谷歌神经网络翻译系统发布后,我们和Google Brain的工程师聊了聊》);近日,来自纽约大约、香港大学和卡内基梅隆大学的研究者又报告了神经机器翻译在实时机器翻译上的突破。
尽管机器学习技术发展迅猛,但谷歌也承认机器翻译还是会犯人类永远不会犯的错误。这一问题增加了实时输入的挑战,让问题变得十分棘手。
实时机器翻译的使用范围涵盖消费者应用(如 Skype Translator)到有望能够帮助专业语言学家显著提高生产力的自适应机器翻译工具。

Graham Neubig
「这项研究的最终目标是语音,」Graham Neubig 告诉 Slator。Neubig 是卡耐基梅隆大学语言技术研究所的助理教授,他与香港大学博士 Jiatao Gu,讲座教授 Victor O.K. Li 和纽约大学的助理教授 Kyunghyun Cho 合作进行了这项研究。

Kyunghyun Cho

Victor O.K. Li
Neubig 解释说:「同步机器翻译是一项能够在说话或是打字的同时实时进行语句翻译的技术。以语音为例,在完整的句子结束之前进行翻译是很重要的,因为一个讲话者说完一句话需要10-20秒,这就意味着需要这么长时间翻译器才能够向用户开始提供翻译内容。这种滞后意味着诸如使用语音翻译技术作为中介流畅地参加一个多方会谈是困难的。」
根据 Neubig 所言,在过去解决这种滞后的一种方法是将输入分割成较短的段而不是直接处理整个句子,然后将各段独立地进行翻译。如果能够找到一个好的分割位置(「比如,在可以彼此分开翻译的短语之间」),就可以减少滞后。这种技术相较之前更快,但是仍然降低了流畅度。
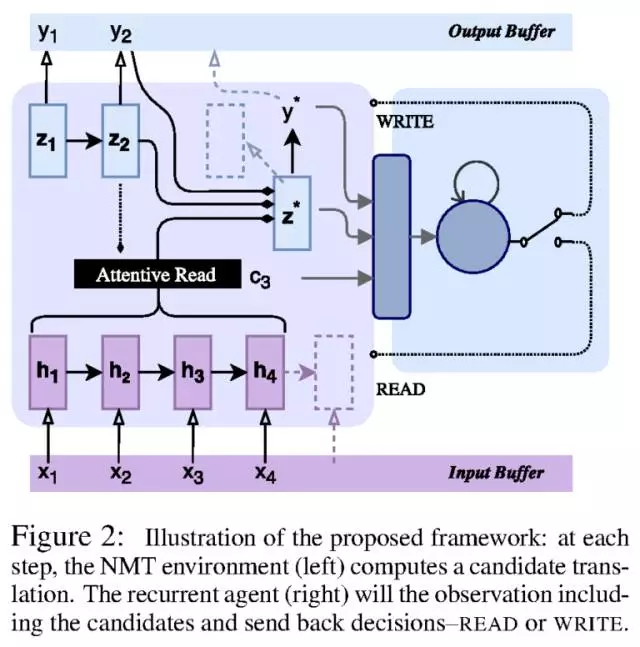
然而,这项研究的与众不同之处是它使用了神经机器翻译(NMT)框架(图2),能够「自动学习什么时候开始翻译词以及什么时候等待更多的输入。」
如果你愿意,可以想象一个等待翻译打字的 NMT 系统,它尝试根据所有已经输入的单词生成下一个单词的翻译。接着,根据神经网络现在的状态(「以及我们对下个翻译的置信度,」Neubig 说),它将会自动决定这个单词是否应当被输出或是等待另外的输入。
「如果答案是『是,输出单词,』那么输出单词同时返回到 1。如果答案是『否,我们不够确定,』那么停止输入同时返回到2,」Neubig 说道。
他补充说,为了系统能够正确地工作,他们要问自己:我们怎样才能为这项工作设计出合适的机器学习算法?我们怎么来确定翻译的便捷性和准确性之间的平衡?我们怎么能恰到好处地搜索最佳翻译?
「这些问题的答案就是本篇论文中技术内容的关键部分,」Neubig 说道。
他指出,「在我们的实验中,我们首次证明了这些算法能在同步翻译上表现得非常好,远远优于之前的基于分割的算法。我们认为这一表现的主要原因在于我们的方法记忆了之前所有输入的单词,并且在选择下一个要翻译的单词的时候对之前所有单词进行了考量,而这对以前基于分割的方法来说并不容易。」
下文是 Slator 对 Graham Neubig 采访关键部分的摘录:
Slator:在第6章,你提到同步翻译是相关工作的典型应用,但是你的论文基本聚焦在文本输入而不是语音输入。那么这项研究的主要实际应用是什么呢?
Neubig:这项研究的最终目标是语音。在这项工作中我们处理文本因为这更易于起步;因为在处理语音的时候还有附加的事项需要考虑,例如语音识别结果导致的附加的不确定性。我们对于在将来能处理语音绝对地感兴趣,这也是我们将要做的事
Slator:为什么你会选择聚焦在 NMT 的这一特定的应用场景?
Neubig:首先,因为这是语音翻译的一个非常重要的问题。其次,因为 NMT 非常适于处理这个问题。NMT 的工作方式是预测句子的下一个单词并且一次一个地输出它们——这正是我们在同步机器翻译系统中所需要的。在这里也考虑了其他很多有趣的算法。
Slator:因为主语和动词之间间距的长短,所以专门选择了德译英的语言组合(图1)吗?

Neubig:是的,这是选择这个语言对的主要原因。先前的同步翻译的工作也因为这个原因聚焦在大量重新排列的语言对上,例如 德语-英语 和 日语-英语。
Slator:如果在德译英中,一旦真正的动词出现在句末,而模型选择了一个明显被误译了的动词,这样的话会发生什么?
Neubig:这是一个非常有趣的问题,我们之前并没有考虑到。真人的同步翻译会返回并改正他们的错误,但是现在还没有机器可以做到这一点。
Slator:你预计这项研究会有什么影响?另外你打算怎样进行接下来的工作?
Neubig:我希望这项研究最终的影响会是语音翻译,当它实现的时候你就不需要为平滑、流畅的输出结果等待很长一段时间。当然,这项工作仅仅是这个方向的一步,在实现这个目标之前,诸如怎样将现有的方法和语音识别系统和合为一体等考虑是要被处理的事。
Slator:你在论文结尾致谢了 Facebook、三星、谷歌、微软和 Nvidia 这些科技巨头?能告诉我们原因吗?
Neubig:这些公司给予了 Kyunghyun 或 Graham 从事与同步 NMT 密切相关的或是通用的 NMT 研究的赞助。然而我们显然不能够代替这些公司发言,我认为他们有兴趣为推进他们认为有前景的研究或教育领域而向学术界提供赞助。不过他们可能会也可能不会这个特定的项目感兴趣。
Slator:特别的,Nvidia 赞助这样一个研究的利害关系是什么?为神经网络、人工智能等等部署的 GPU 已经成为他们业务的一个如此大的推动力了吗?
Neubig:我认为他们的确为机器学习使用 GPU 而感到兴奋;但是,当然,再次说明,我们不能代替他们发言。